

NVIDIA is bailing out CoreWeave. Independence of Neoclouds is dead.
NVIDIA has officially solidified its transition toward a vertical trust model, utilizing CoreWeave as a vehicle for direct expansion into the cloud sector.

NVIDIA has officially solidified its transition toward a vertical trust model, utilizing CoreWeave as a vehicle for direct expansion into the cloud sector. This $2B investment, relative to CoreWeave’s annual revenue of $6B, appears to be an attempt to stabilize the balance sheet of the industry’s most highly leveraged player and restore creditor confidence ahead of a massive CapEx cycle. However, the underlying financial math is far more ruthless. When considering the ambition to construct AI factories with a total capacity of 5 GW, at a current cost of $40 billion per 1 GW, the total project budget reaches $200–250 billion. Of this amount, approximately 60% ($120–150 billion) is attributed to NVIDIA’s own chips and networking architecture.
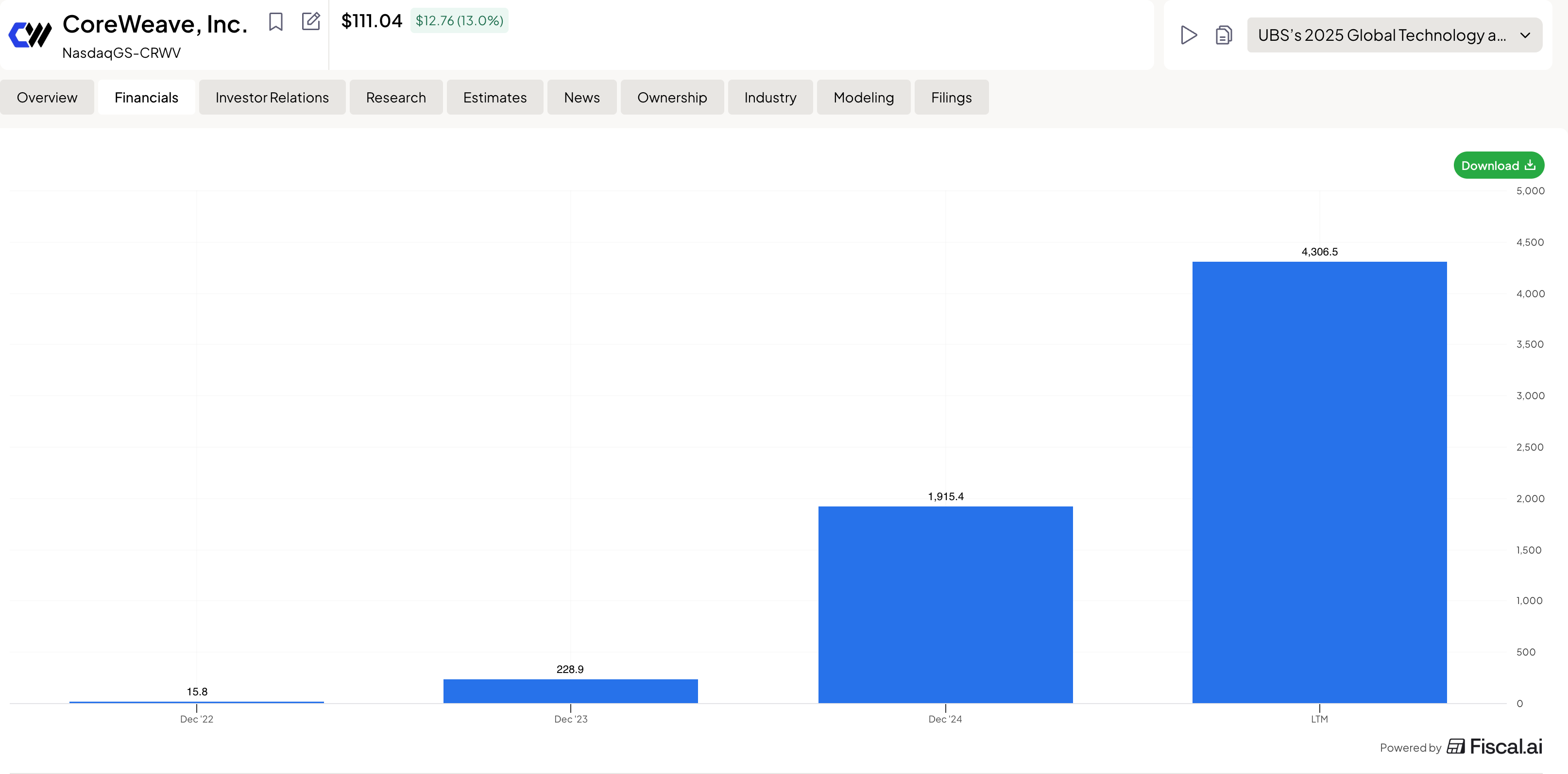
Building 1GW costs roughly $15B, meaning $75B for the entire build-out,a figure that is much more grounded and aligns with the investment Huang promised OpenAI but has yet to deliver. Outfitting these factories with chips is a matter of both financial and standard engineering, which is certainly feasible. The task seems entirely manageable, especially since building from scratch isn’t the only option. They could acquire IREN/Cipher/HUT8, which already have sites ready to go, or they could lease capacity and pass the costs onto the consumer through service fees. With $500B in revenue, there are plenty of ways to make it work. Meanwhile, under Intrator, CoreWeave has lost all independence and is forced to look for a buyer unless this entire play was designed from the start as a blunt-force market grab at any cost.
By launching Vera, NVIDIA erases this barrier. The Vera CPU and the Rubin GPU now reside on a unified NVLink 6 bus with bandwidth that standard server solutions cannot touch. The investment in CoreWeave creates a proving ground where this synergy operates in a vacuum. NVIDIA needs to prove that their “closed stack” is superior, and doing so through a controlled provider is the fastest path to market dominance.
A Direct Counter to Microsoft’s Silicon Ambitions
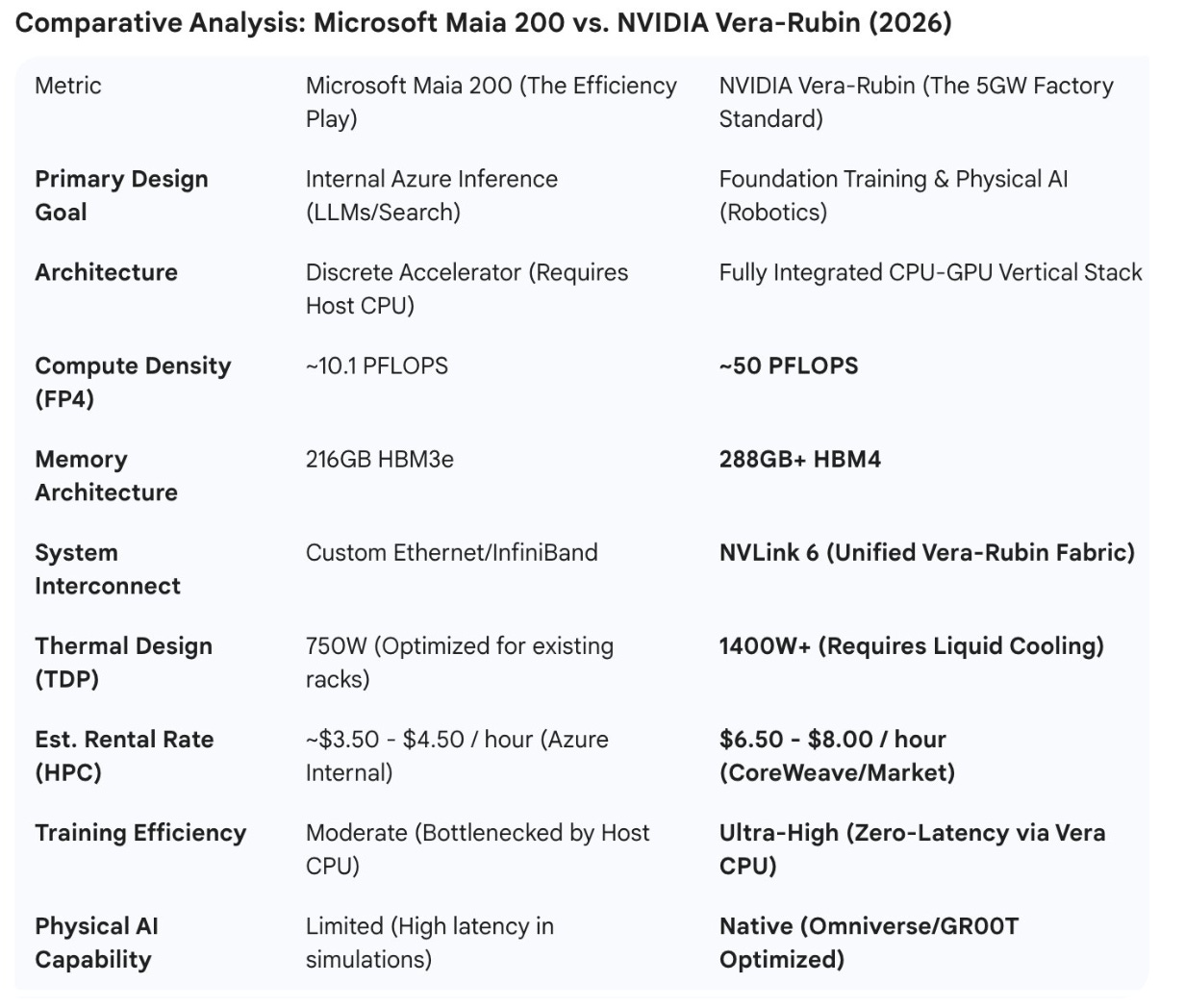
The debut of Vera was timed specifically to blunt the impact of the Microsoft Maia 200. Microsoft, Google, and Amazon have been aggressively developing internal silicon to de-risk their reliance on NVIDIA and relegate them to a mere component supplier. If NVIDIA had remained only in the GPU segment, it risked becoming an “appendage” in Big Tech clouds that control the central processor and system logic.
Vera changes the rules: NVIDIA now dictates the entire server configuration. Through CoreWeave, they are rolling out a “factory standard” that excises Intel and AMD entirely. This puts Microsoft in a defensive position. While the Maia 200 is an impressive step forward featuring custom silicon optimized for high-bandwidth sub-network processing and improved FP8 efficiency for inference, it remains an attempt to optimize a specific part of the chain within a legacy cloud framework. In contrast, NVIDIA is building a purpose-built environment where the training and execution of Physical AI are seamless. Huang is telling the market: “If you want to build the future of robotics, you don’t need a general-purpose cloud; you need our specialized factories.”
The Economics of Control and Competitor Displacement
The financial logic is even more pragmatic. In the construction of a 1GW facility, a significant portion of the margin previously leaked to server platform and CPU manufacturers. With Vera, NVIDIA captures that entire pie. In the bill of materials for a CoreWeave data center, almost every line item is now an NVIDIA product.
This allows for maximum financial engineering. NVIDIA can subsidize Vera shipments to freeze competitors out of the data center or offer bundled long-term lease packages that are economically impossible for anyone assembling servers from disparate vendors. Ultimately, Vera is the lock on the door of these 5GW facilities: entering with third-party hardware will be technically suboptimal, leaving NVIDIA’s integrated stack as the only viable path for next-generation compute.
The Microsoft Strategy: Defensive Optimization
Microsoft is using the Maia 200 to survive the “token war.” By building their own silicon, they avoid the “NVIDIA tax” for their internal services (Bing, Office 365, GPT-5.2 inference). However, the Maia 200 remains a discrete component. It still has to communicate with a host CPU, creating a latency floor that makes it suboptimal for the massive, real-time physical simulations required by the next generation of robotics. Microsoft is essentially building a “cheaper typewriter” for the AI era.
The NVIDIA Strategy: Offensive VerticalizationThe Vera-Rubin stack, deployed via the 5GW CoreWeave build-out, is designed to make general-purpose clouds like Azure obsolete for high-end developers. By integrating the Vera CPU directly onto the same bus as the Rubin GPU, NVIDIA has eliminated the “PCIe bottleneck.”
Market Leverage: In a 5GW “Factory,” NVIDIA can process simulations 5-10x faster than a Maia-based cluster.
Financial Engineering: Because NVIDIA owns the entire bill of materials (CPU, GPU, Networking), they can manipulate the “rental price” in CoreWeave to underprice Microsoft’s Azure offerings while maintaining higher net margins.
The 5GW Reality CheckFor a founder building Physical AI, the higher hourly cost of a Vera-Rubin instance is irrelevant compared to the time-to-market. If NVIDIA’s stack can train a humanoid robot’s motor skills in 2 weeks while Microsoft’s Maia cluster takes 8 weeks due to CPU-GPU latency, the “expensive” NVIDIA chip is actually the cheaper option. This is the “Industrial Trap” NVIDIA is setting: they are building the only infrastructure capable of handling the sheer scale of 2026-era Physical AI.
The $20 billion acquisition of Groq, finalized in late 2025, serves as the cornerstone of the 5GW architecture. While the Vera CPU was engineered to eliminate latency between the processor and the GPU, Groq’s technology is the missing link required to drive Physical AI with the speed of a human reflex.
Groq LPU: Why It Is Mission-Critical for Robotics
Traditional GPUs, including the latest Rubin architecture, excel at parallel computing but struggle during the inference stage due to the “Memory Wall.” To execute a single movement or generate a specific token, a GPU must constantly access external HBM (High Bandwidth Memory). This creates micro-delays—jitter—that are negligible in text generation but fatal for an 80kg humanoid robot operating in the physical world.
Groq’s LPU (Language Processing Unit) architecture, built on SRAM, solves this problem fundamentally through:
Determinism: Groq chips lack dynamic scheduling. The compiler knows exactly which nanosecond data will pass through a specific transistor. This is “hardware with a predictable future.”
Speed: While a standard GPU might output 100–200 tokens per second, the Groq LPU hits 1600+. In the context of Physical AI, this means a robot can “think through” its actions ten times faster than they occur in reality.
The Vera-Rubin-Groq Synergy: Birth of “Instinctive AI”
NVIDIA’s decision to acquire Groq—its largest deal since Mellanox—was driven by the need to integrate deterministic inference directly into the Vera-Rubin stack. Within a single rack of a 5GW CoreWeave data center, the labor is now divided to mimic biological systems:
Rubin GPU: Handles the heavy lifting—foundational training and massive physical simulations in Omniverse.
Vera CPU: Manages high-level logic and path planning.
Groq LPU (Now NVIDIA IP): Acts as the “reflex arc.”
This tri-part architecture transforms the robot from a lagging machine into an agent with biological reaction speeds. By swallowing Groq, NVIDIA neutralized the only competitor capable of offering Microsoft or Google an architecture for ultra-fast inference. If you want a robot to react to a moving object in less than 100ms, you are now physically tethered to the NVIDIA stack.
Market Capture: From “Smart Words” to “Smart Movements”
The Groq acquisition is Jensen Huang’s admission that the era of the “general-purpose GPU” is over. Physical AI demands specialized, real-time inference.
Microsoft, with the Maia 200, is playing a defensive game, optimizing for standard cloud efficiency and text-based workloads.
NVIDIA, by absorbing Groq, is building Real-Time AI.
In the context of the 5GW build-out with CoreWeave, these data centers are evolving into the “central nervous system” for millions of autonomous agents. NVIDIA has effectively “seeded” its future factories with technology that renders any third-party silicon—including Microsoft’s Maia or Google’s TPU—obsolete for real-world physical applications. NVIDIA has moved beyond being a chip vendor; it has become the architect of the physical world’s latency standards.
CoreWeave = Operational Arm
The 5GW roadmap signals a permanent shift: CoreWeave can no longer be viewed as an independent cloud provider, but rather as the operational arm of NVIDIA’s vertical monopoly. The $2B investment is a down payment on a future where CoreWeave is the exclusive showroom for the Vera-Rubin-Groq stack. By providing the equity to de-risk these massive infrastructure builds, NVIDIA has effectively turned CoreWeave into a “captured” entity—a strategic proxy that allows NVIDIA to control the cloud layer without the regulatory friction of a direct acquisition.
For small-cap miners like IREN 0.00%↑ and CIFR 0.00%↑ , this new reality is a double-edged sword. On one hand, their valuation is no longer tied to the volatility of Bitcoin, but to their status as “Grid Gatekeepers.” In a world where NVIDIA is scrambling to secure 5GW of power, a miner with 500MW of “ready-to-plug” capacity and a 20-year Power Purchase Agreement (PPA) is more valuable for its substation than its mining rigs. They have become the land-owners in an era of industrial AI expansion.
Independence is dead
However, the “independence” of these smaller players is under immediate threat. As NVIDIA builds out its 5GW empire through CoreWeave, it creates a massive “gravity well” for power and talent. IREN and WULF and others now face a stark choice: either they become high-margin infrastructure partners for the NVIDIA-CoreWeave machine, or they become hostile takeover targets.
The reality of 2026 is that independence is dead. These smaller players are being forced into a consolidation deathmatch. They will either be compelled to merge with one another to gain the multi-gigawatt scale required to negotiate with chip titans, or they will inevitably fall under the “protective” wing of Google or Microsoft.
We are seeing the formation of infrastructure protectorates: CIFR is already leaning into Google’s orbit via the Fluidstack deal to secure TPU v6 access, while IREN is positioning itself as Microsoft’s strategic partner. Any attempt to remain a “neutral” operator is now a suicide mission; without a seat at the table of the big three, these companies lose access to the next-generation silicon and the capital required to stay relevant.
This publication is for educational and informational purposes only and does not constitute financial, investment, or trading advice. Readers are solely responsible for their own investment decisions. The author may hold positions in the securities mentioned.
Fascinating take on NVIDIA’s verticalization strategy. I like how you frame Vera + Rubin as a move from component supplier to full-stack control, with CoreWeave as the proving ground. The economics of owning the entire bill of materials really changes the game. What do you see as the biggest risk to this strategy: execution at scale or hyperscalers accelerating their own silicon even faster?
I’ve subscribed and would be happy to support each other.
Jorrit
When a business becomes to powerful they can just buying themselves into anything. Absurd.